Zwei Personengruppen
Was finden wir wirklich in unseren Daten?
Bisher haben wir die 400 Personen in unserem Datensatz lediglich danach unterschieden, ob sie zahlungsfähig sind (dunkelblau) oder nicht (hellblau).
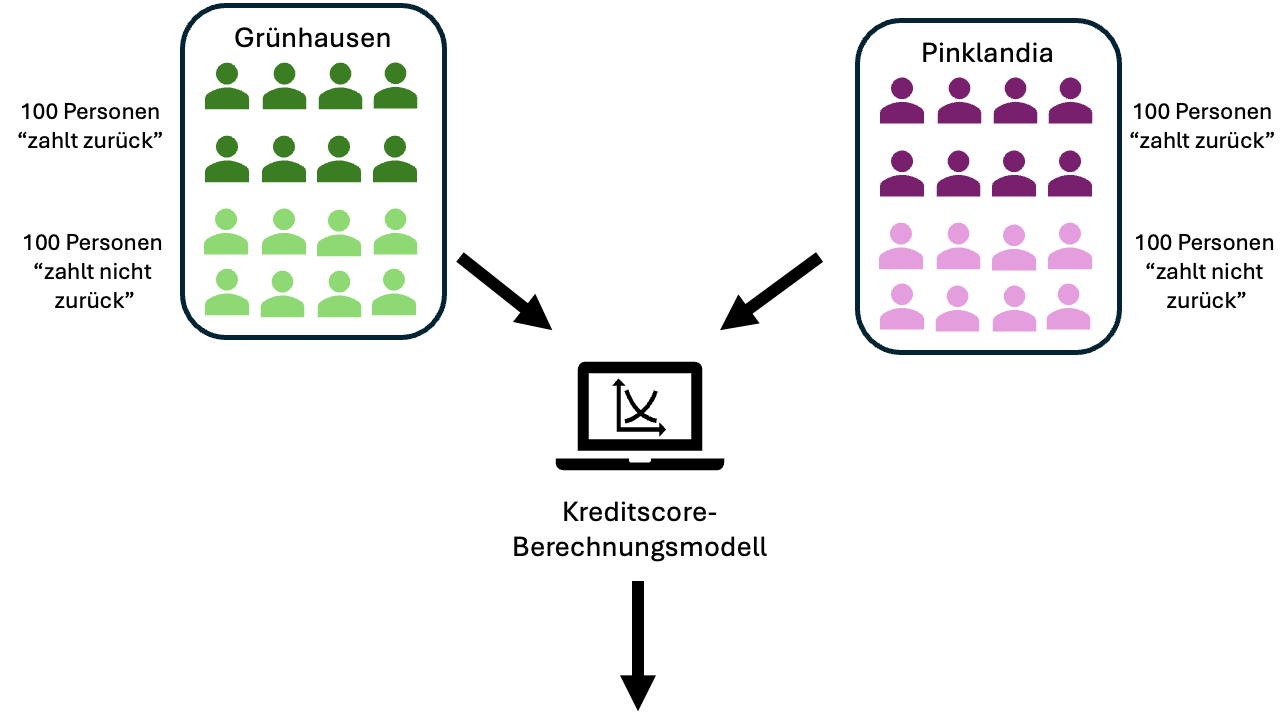
Wir wissen allerdings noch mehr. Unser Datensatz besteht tatsächlich aus zwei Bevölkerungsgruppen, die sich in einem wesentlichen Merkmal unterscheiden. Dieses Merkmal könnte beispielsweise das Geschlecht, die ethnische Herkunft oder das Alter (alt vs. jung) sein. In unserem Datenbeispiel unterscheiden wir die Personen nach ihrer fiktiven Herkunft aus “Grünhausen” und “Pinklandia”.
In beiden Bevölkerungsgruppen gibt es je 100 Personen, die zahlungsfähig sind, und 100 Personen, die nicht zahlungsfähig sind. Damit ist es in beiden Populationen gleichwahrscheinlich, dass eine Person zahlungsfähig ist.
Die Anwendung des Kreditscore-Modells liefert jedoch deutlich unterschiedliche Verteilungen für die beiden Personengruppen. Dies wird in den folgenden Grafiken ersichtlich.
- Finde möglichst viele Kritikpunkte an diesem Ansatz
- Argumentiere aus Sicht der Bank, wieso das ein guter Ansatz ist.